Editor’s Note: This post contains some uncommon Unicode characters, some of which may not display properly on older systems.
In May 2020 the Distributed Proofreaders (DP) site moved over to using the Unicode UTF-8 character base. “This is a very major change,” said General Manager Linda Hamilton. “This move has been a long-term objective for many years.” (For more information on this huge improvement, see the DP Wiki article Site conversion to Unicode.) Now, instead of being limited to about 200 assorted letters, numbers, and squiggles, DP has over a million to choose from.
We started modestly, providing a very few extra characters, such as the “œ” ligature often found in older books in words like Œdipus or cœlacanth. Soon though, DP site developers were picking up the pace, providing more and more additional character suites that Project Managers can assign to their projects. We rolled out three character suites for different European languages – with letters like ĝ, Đ, or ł; Basic Greek and Polytonic Greek character suites; and one for characters found in medieval books such as Ƿ or ȳ. In addition, Project Managers can now add individual Unicode characters to a project where they’re needed. These characters, which can include less familiar specimens such as ŧ ꝓ ᴚ ♅ ◘, show up in a “Custom” character suite on the proofreading screen.
All Greek to us
How does this really benefit our work in DP? Mainly, the Unicode-based encoding allows us to support languages that use characters outside the “Latin-1” character suite, which was what we had available before then.
Let’s take one important example: Ancient Greek. Why important? Because many of the books we work on, from the 19th century or before, do contain Greek words or whole passages in Greek. The writers of the time took it for granted that readers of the more scholarly type of book would have learnt Greek (along with Latin) as part of their education.
We reported here a few months ago about how DP handled Grote’s History of Greece, a monumental work with thousands of footnotes containing Greek text. Much of the work there fell to the Post-Processor, the person who prepares a project for final publication after it has all been proofread. With Unicode, the proofreaders can have a share of the fun!
Formerly, the proofreaders didn’t have the use of Greek characters. To represent the text during proofreading, a roundabout process was necessary in which proofreaders produced a transliterated version of the Greek written in our familiar Roman alphabet, like [Greek: mêde nein mêde grammata], to be transformed back into the original Greek – μηδὲ νεῖν μηδὲ γράμματα – by the Post-Processor. But now, the proofreaders can produce a correct text, drawing on a complete set of Greek characters. This is how the relevant part of the proofreading screen looks for a project that includes a Greek character set:

Asking proofreaders to work with Greek letters is also more practicable now that Optical Character Recognition (OCR) software has become better at reading Greek. Take a look at what OCR made of a page of Greek in 2005:

Looks like the book was written in Klingon doesn’t it? Now compare this, from 2020:
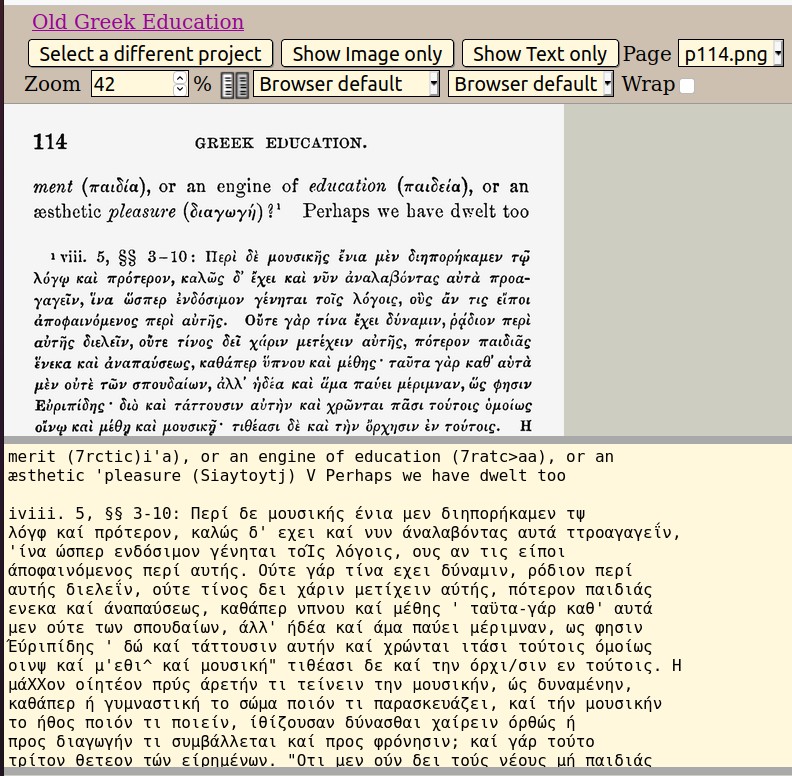
Still far from perfect, but good enough that proofreaders don’t have to retype the whole thing from scratch. Using the expanded character set, they can now correct the Greek text coming from OCR, just as they correct text in their own language.
The Mercury goes up
It’s the same with other types of characters. If proofreaders meet an unfamiliar letter in a medieval book, instead of typing [yogh] (for example), they can now input the actual letter ȝ. And we continue to add more character sets to meet the needs of our varied projects. Among recent ones is a set of characters used in Romanized forms of languages such as Arabic, Hebrew, and Sanskrit, so we can reproduce accurate transliterations of names such as ʿAlaʾuddīn or Mahābhārata or Viṣṇu (which previously had to be proofed as Vi[s.][n.]u). There’s also a “symbols collection,” including astronomical, zodiac, apothecary, and music symbols. With this collection, if we’re proofreading an astrological book, instead of [Mercury] we can now simply add ☿. Recipe for a bygone apothecary’s potion? Not [**ounce], but ℥. And so on.
So with Unicode, proofreaders know that someone else won’t need to come along and change all the awkward symbols later. Now they can do the whole job and produce a precise digital version of the original page, no matter what characters are on it!
This post was contributed by Neil M., a Distributed Proofreaders volunteer.



Very nice, and good to know we are going into the direction of full Unicode support. I’ve been running numerous projects that required special characters or foreign scripts, and the use of codes always made that more cumbersome and less WYSIWYG. There are several downsides to this as well.
1. Sometimes glyphs look very much like each other, it is very easy to confuse a Latin A with a Greek Α or a Cyrillic А, and even a Cherokee Ꭺ. You will need some precautions to prevent such a mix-up, especially if we use click-to-enter interfaces.
2. Click-to-enter is nice for a few words, using a keyboard is typically much faster (but requires training); I still find myself typing Greek in transcription faster than using a mouse, same is for those obnoxious codes as [n.] (which are converted on the fly, which is great)
3. Some books require combining characters, which introduce a new set of challenges. Also nasty are the emoji variants of some characters, such as ♊︎, which can appear as ♊️ if no proper variant selector is included. For older books, you never want the emoji style variant.
4. Last, but not least, support for right-to-left scripts, like Hebrew and Arabic will open a can of worms: in mixed text, words and phrases might start flipping around when you try to enter characters with a different directionality. It is for this reason, I still prefer to deal with those scripts in transcription.
Nevertheless, many thanks to those people making this work on PGDP.
I really appreciate your effort in bringing this ancient materials of value to us. Thank you team Project Gutenberg.
I currently point proofers at this page (https://www.translatum.gr/converter/beta-code.htm) to be able to enter Greek in Beta-code on a normal keyboard in the right pane, and immediately see the result in (polytonic) Greek in the left pane, which can be copied, and pasted. For anything more than a single word, this works faster than point-and-click for all who do not have or know how to use a native keyboard.